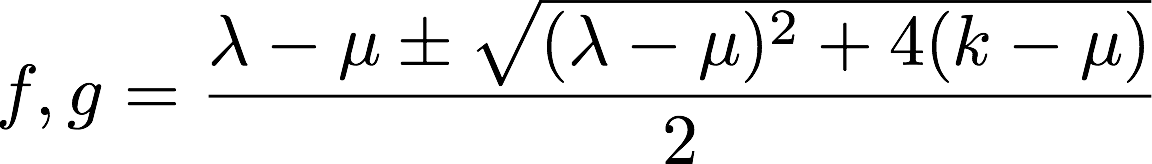0. 背景
グラフ理論とは文字通り, グラフについて解析する分野です. グラフ理論のモチベーションとしては, 「最小全域木」「最大マッチング」「最大フロー」などのアルゴリズムを考える際に対象となるオブジェクト(この例で言えば全域木, マッチング, フロー)に対する「良い」特徴付けや性質(例えばHallの結婚定理, グラフマトロイドの基, 交互増加道, 残余ネットワークに関するものなど)を与えるという, アルゴリズム上のモチベーションが最も大きいんじゃないかと思います.
しかしそれとは別に純粋数学寄りな一面もあります. グラフ理論の一分野に「Algebraic graph theory」というのがあります. 直訳すると「代数的グラフ理論」で, この分野はグラフの特徴を代数的に解析するもしくは代数的に「綺麗な」グラフを構成したり, Tutte多項式といった興味深い不変量について解析しています. ここで言う「代数」とは線形代数(スペクトラムグラフ理論)や群(Cayley graph)などです. 面白いことに正則グラフ(全ての頂点の次数がある定数に等しいグラフ)に対するゼータ関数としてIhara zeta function というものが知られていて, Ihara zeta function を用いてラマヌジャングラフと呼ばれるスペクトラムグラフ理論において非常に重要なグラフの特徴づけを与えられています.
グラフの持つ美しい性質の解析の一方で,
こちらの記事で紹介したような「小直径グラフを構成する」や「彩色数と内周(girth)が共に大きいグラフ」といった, 普通のグラフでは満たされないような性質を満たすグラフをalgebraic graph theoryの道具を用いて巧妙に構成するという研究も有ります.
今回の記事では 強正則グラフ (strongly regular graph) と呼ばれるグラフについて, スペクトラムグラフ理論においてしばしば用いられるテクニック(=線形代数)を用いて解析していきます. 更にその応用として, グラフ理論における二つの
未解決問題(Moore graph と Conway 99 problem)について考察してみます. あらかじめ記しておきますが, 本記事は予想以上に線形代数成分が強いです (というかグラフ理論成分は少なめです).
1. 強正則グラフ
グラフ$G$に対し, その頂点$v$に隣接する頂点の全体を$N(v)$で表します.
$n$頂点の$k$-正則グラフ$G$ (全ての頂点の次数が$k$に等しいグラフ) が以下の全ての性質を満たすとき, $G$はパラメータ$(n,k,\lambda,\mu)$を持つ
強正則グラフであると言います.
- 任意の隣接する二頂点$u,v$に対して, $|N(u)\cap N(v)|$がある定数$\lambda$に等しい.
- 任意の隣接しない二頂点$u,v$に対して, $|N(u)\cap N(v)|$がある定数$\mu$に等しい.
イメージとしてはこんな感じです:
特に, $\mu>0$の場合はグラフの直径は$2$以下となります. $\mu=0$の場合はグラフは非連結で, 各連結成分はサイズ$\lambda+2$の完全グラフになっていて次数は$k=\lambda-1$となります.
例:
・長さ5の閉路 : $(n,k,\lambda,\mu)=(5,2,0,1)$.
・Petersen graph : $(n,k,\lambda,\mu)=(10,3,0,1)$.
 |
| Petersen graph |
・$n$頂点の完全グラフ : $(n,k,\lambda,\mu)=(n,n-1,n-2,0)$.
・長さ$3$の閉路 : $(n,k,\lambda,\mu)=(3,2,1,0)$.
$\lambda$は三角形の個数, $\mu$は四角形の個数を規定している感じになっています.
2. 強正則グラフのスペクトル
$G$を$(n,k,\lambda,\mu)$をパラメータに持つ強正則グラフとします. 更に$\mu\neq 0$を仮定します. $G$の隣接行列を$A$とします. すなわち
と定めます. 今回の目的は$A$の全ての固有値を特定することです. 固有値を求めてそこから得られる様々な条件を考えることによって, 与えられたパラメータ$(n,k,\lambda,\mu)$に対応する強正則グラフの存在性について議論することが出来ます (後述).
$i\neq j$に対し, $(A^2)_{ij}$は頂点$i$から頂点$j$への長さ2のパスの本数に等しいはずです. $ij$が隣接しているときはこの値は$\lambda$と等しく, そうでないときは$\mu$に等しくなります (上図参照). $i=j$に対しては$A^2_{ij}$は次数に等しいので$k$となります. 以上より
なので,
$A^2+(\mu-\lambda)A=(k-\mu)I+\mu J$ ...(1)
となります. ここで $I$ は$n\times n$の単位行列, $J$は全ての要素が1に等しい$n\times n$行列です. 即ち強正則グラフの隣接行列は行列の二次方程式が成り立ちます.
$A$は$k$-正則グラフなので, 各行に含まれる$1$の個数(=次数)は全て$k$に等しいはずです. すなわち $A\mathbb{j}=k\mathbb{j}$ が成り立ちます. ここで$\mathbb{j}\in\mathbb{R}^n$は全要素が$1$の列ベクトルです. 更に$A$対称行列なので全ての固有値は実数であり, しかも最大固有値は$k$に等しく, ($\mu>0$よりグラフは連結なので, $A$は行列として既約であるため, ペロン=フロベニウスの定理より)最大固有値の多重度は$1$となります. したがって$A$の他の固有値$\theta$に対応する固有ベクトル$x$は必ず$\mathbb{j}$と直交します. このベクトル$x$を二次方程式の両辺に掛けると, ($Jx=\mathbb{j}\mathbb{j}^{T}=0$に留意して)
$(A^2+(\mu-\lambda)A)x = (\theta^2+(\mu-\lambda)\theta)x = (k-\mu)x$
となります. したがって$\theta$は以下の二次方程式:
$\theta^2+(\mu-\lambda)\theta-(k-\mu)=0$
の解になっているので,
以上より, $A$の固有値は三種類しかなく, それらは
となることが分かりました. 更に, $A$に関する二次方程式の両辺に$\mathbb{j}$を掛けると
$k^2+(\mu-\lambda)k=k-\mu+\mu n$ ...(2)
即ち, $k(k-\lambda-1)=(n-k-1)\mu$ が成り立ちます.
最後に, それぞれの多重度を求めてみましょう.
とおいてそれぞれの多重度を$s,t$とおきます. すると$A$のトレース(=対角成分の和=固有値の和)は$0$に等しく, 固有値$k$の多重度は$1$であることも合わせると
$fs+gt+k=0$, $s+t=n-1$
となり, これを連立させると

...(3)
が成り立ちます. 即ち $(n,k,\lambda,\mu)$をパラメータとして持つような強正則グラフが存在するためには, これら四つの値が (2)を満たしかつ(3)で与えられる$s,t$が整数とならなければいけません. これらの条件を使うことによって与えられたパラメータに対応する強連結グラフの存在性について議論することが出来ます.
先ほどみたように, 連結な強正則グラフの固有値は3種類しかありません. 面白いことに逆も成り立つことが知られています:
定理1:
$G$を連結な$k$-正則グラフで完全グラフでないものとする. $G$の隣接行列が三つの相異なる固有値$k>s>t$を持つとする. このとき, $G$は強正則グラフである.
また一般に, 固有値の種類数はグラフ(強正則でなくても良い)の直径を上から抑えるということが知られています:
定理2:
連結な$G$に対してその隣接行列が持つ相異なる固有値の個数を$m$とする. $G$の直径は$m-1$以下である.
応用1: Moore graph の存在性
Moore graph とは簡単に言うと「直径$D$の$d$-正則グラフの中で最も頂点を多く含んでいるグラフ」のことです. 詳しくは
こちらの記事に書いてあります. Moore graphは
- 直径$>2$の場合は存在しない
- 直径$=2$かつ$d\not \in \{2,3,7,57\}$ の場合は存在しない.
ことが示されています. 今回は二つ目の事実をこれまでの議論を使って示していきます.
こちらの記事より, 直径2のグラフ$G$が Moore graph であることの必要十分条件は, $G$が三角形と四角形を含まないことです. 更に, 明らかに$n=k^2+1$となります). 従って, $G$はパラメータ$(n,k,\lambda,\mu)=(k^2+1,k,0,1)$を持つ強正則グラフとなっていることに注意します($n=k^2+1$は今回導出した(2)の条件に$\lambda=0,\mu=1$を代入することで導出できます).
(3)の整数性条件を考えます. パラメータを代入して計算すると
即ち, $k^2-2k=0$ もしくは $4k-3=p^2$ ($p\in\mathbb{N}$) が必要条件となります. $k^2-2k=0$, 即ち$k=2$に対しては長さ$5$の閉路が対応しています. 2番目の条件より, $k=(p^2+3)/4$ を $s$ に代入すると,
$s=\frac{p^4+6p^2+9}{32}+\frac{p^4-2p^2-15}{32p} = \frac{p^5+p^4+6p^3-2p^2+9p-15}{32p}$
整理すると
$p^5+p^4+6p^3-2p^2+(9-32s)p=15$
従って$p$は$15$を割り切るので, $p\in \{1,3,5,15\}$となり, それぞれの$p$を$4k-3=p^2$に代入ことにより, $k=1,3,7,57$ が得られます. $k=1$の時は$n=k^2+1=2$より, グラフは$K_2$となります (直径2ではないのでこれは除外します).
従って, 直径2のMoore graphが存在するならば, $k\in \{2,3,7,57\}$ が成り立ちます.
応用2: Conway 99 graph problem
元ネタ : https://oeis.org/A248380/a248380.pdf
関連文献 : https://arxiv.org/abs/1707.08047
こちらの問題はグラフ理論というよりは, Conwayが出した未解決な問題であり, 解けたら1000ドルもらえるというプチミレニアム未解決問題です. 具体的には次のような問題です:
問題: 以下の二つの性質を満たす$99$頂点のグラフは存在するか否か.
- 任意の隣接している二頂点$u,v$に対して, $u,v$を含む三角形が唯一存在する.
- 任意の隣接していない二頂点$u,v$に対して, $u,v$を対角線上に含むような四角形が唯一存在する.
イメージとしては次のような感じです:
 |
| 三角形は被ってはいけない. 四角形は二辺を共有してはいけない. |
本記事では条件1を三角形条件, 条件2を四角形条件と呼ぶことにします (番号が乱立して可読性が下がるため)
問題を見た感じだと正則グラフには見えないのですが, もし所望のグラフ$G$が存在するとして, それが$k$-正則であったならば, $G$はパラメータ$(99,k,1,1)$を持つ強正則グラフであることが分かります. すると(2)の条件より, $k=14$が出てきます. そもそもなぜ頂点数が99なのでしょうか?この記事ではより一般に, パラメータ$(n,k,1,1)$を持つ強正則グラフについて考え, どのような$n$と$k$に対してそのグラフが存在するのかについて考えていきます. まず明らかですが, $n=3,k=2$に対しては$K_3$が所望の性質を満たすことが確認できます(非隣接点が存在しないため). これ以外に所望のグラフはあるのでしょうか?
実は, 所望のグラフが存在するとしたら, そのグラフは必ず正則であることが次のようにして証明できます:
$G=(V,E)$の頂点数を$n$とします. $G$において隣接している二頂点$u,v$を任意にとってきます. するとある頂点$w\in V\backslash \{u,v\}$が一意に存在して$uvw$が三角形となります. 更に$n\geq 4$のとき, $G$の直径は$2$であり, $k\geq 3$となる ($k=2$ならば$n=3$となってしまうから). 従って$u$に隣接する頂点$z\in V\backslash \{v,w\}$が存在し, この$z$はどれも$v$には隣接していない (そうでないならば, $uvz$が三角形条件に反する. 下図1参照).
 |
| 図1 : $z$と$v$は隣接してはいけない. |
そこで$z, v$に対して四角形条件を適用すると, $zv$を対角線として持つような四角形$uvz'z$が存在することになります. 特にこの四角形は一意なので, $z$に対して$z'$は唯一定まります (図2). 特に$z'\in N(v)$に注意します.
 |
| 図2. $vz$を対角線に持つような四角形がとれる. 一方で$z$に対して複数の$z'$をとることは出来ない. |
そこで写像$z\mapsto z'\in N(v)$を考えると, これは単射になっています. $z_1\neq z_2 \in N(u)$に対して$z_1\mapsto z'$, $z_2\mapsto z'$となると四角形条件に反するからです.
 |
| 図3: $z_1,z_2 \mapsto z'$となると$uz'$を対角線に持つ四角形が二つできてしまう. |
従って, 単射$N(u)\to N(v)$が構成できた(実際は全単射になっている)ので, $|N(u)|\leq |N(v)|$. 同様にして逆も言えるので, $|N(u)|=|N(v)|$. $G$は連結なので, どの頂点の次数もある定数に等しい. よって$G$は正則である.
以上より, 議論すべきグラフは正則なので, パラメータ$(n,k,1,1)$を持つ強正則グラフです. 更に(2)の条件より, $n=\frac{k^2}{2}+1$となります. $n$の整数性から$k$が偶数であることも直ちに従います. さらに, 固有値の多重度の整数性条件から

すなわち$k^2-4k=0$, $4k-7=p^2$となります.
$k^2-4k=k(k-4)=0$の場合は$k=4$となり, 対応する$n$は$n=\frac{k^2}{2}+1=9$.
$4k-7=p^2$の場合は$k=(p^2+7)/4$を$s$に代入することにより

従って, $p^5+p^4+14p^3-2p^2+(49-64s)p=63$ となるので, $p$は$63$を割り切ります. 即ち$p\in \{1,3,7,9,21,63\}$. 対応する次数$k$は$k\in\{2,4,14,22,112,994\}$.
まとめると, $(n,k,1,1)$をパラメータとして持つ強正則グラフが存在するための十分条件は(計算ミスがなければ)

実際, $(n,k)=(3,2)$に対しては$C_3$が対応しています.
しかし$(n,k)=(9,4)$に対しては存在しないことが示せます(三角形条件と四角形条件を使って局所的な構造を絞ることによって示せますがあまり証明としては綺麗ではありません).
こちらにあるように, $(n,k)=(9,4)$は具体的にグラフが構成でき, 隣の研究室の後輩に教えられたのですが, $K_{3,3}$の線グラフ(辺と頂点を交換したグラフ)が条件を満たしています. (2018年7月24日追記) $(n,k)=(99,4)$はConwayの99問題に対応しています. 他にも三つほどヤバそうな$(n,k)$がありますが, とりあえず有限個であることは以上の議論より示すことが出来ました.
要するに「99」という数字の本質は線形代数的な議論によって導かれます. また, Moore graphにおいても「次数57」の条件は同様な議論から導出できます. 即ち「良い性質を持った」グラフの存在性については未だに線形代数的な議論によってしか条件を絞り込むことが出来ていないというのが現状です. 従って今回提示した二つの未解決問題を解くためには, 線形代数から少し離れたアプローチ, もしくはよりグラフ理論っぽいアプローチから新たな必要条件を導出するしかないんじゃないかなぁとなんとなく思っています.
3. まとめ
今回の記事では「スペクトラムグラフ理論」と言いながらほとんど「スペクトラムグラフ」感が感じられないものだったので, あまりその凄さが通じなかったのかもしれません. しかし実はスペクトラムグラフ理論の技法はグラフの構造上の特徴の情報を得ることが出来ます. 例えば, $(n,k,1,1)=(99,14,1,1)$をパラメータに持つ強正則グラフ(Conwayの問題におけるグラフ)が存在するならば, その最大独立点集合のサイズが高々22であり, 彩色数は5以上である, ということを証明することが出来ます (驚くべき証明があるのですが余白がないので省略します).
そして実際に今回示した手法によってMoore graph や Conway problem に対してある程度までの必要条件を導出することが出来ました. なお今回のConway problemに関する結果については僕は論文でも見たことはなく, (載っている論文がぱっと見見つからないという意味で)新しいものなのかもしれませんが, 教科書に載っている程度の初等的な議論によって得られる結果なので「プロ」の研究者にとっては既知の情報かとは思います. また, 今回の議論は次を参考文献として提示します.
- "Elementary Number Theory, Group Theory and Ramanujan Graphs", Giuliana Davidoff, Mount Holyoke College, Massachusetts Peter Sarnak, (2003)
こちらの本はグラフスペクトル理論の初歩的な部分について解説していて, Ramanujan graph についての話題が書いてあります. 前提知識もあまり必要でなく, 非常に読みやすかったです.
- "Topics in Graph Automorphisms and Reconstruction", Josef Lauri, University of Malta Raffaele Scapellato, Politecnico di Milano, (2016)
こちらの本は algebraic graph theory に関わる話題として automorphism (vertex-transitivityなど)や, グラフ理論における非常に有名な未解決問題: reconstruction conjecture について紹介しています. strongly regular graph, Moore graphについて節が割かれています.